What is an LLM and what is its purpose?
A Large Language Model (LLM) is a type of machine learning model trained on vast amounts of textual data to understand and generate natural language. Well-known LLMs include ChatGPT, Claude and Gemini. These models are capable of performing various tasks such as answering questions, summarizing texts, translating languages, understand and analyze search intent and even generating new content like articles, poetry, marketing material, and computer code.
LLMs are typically hosted on cloud infrastructures due to the enormous computational resources required during the training phase. However, once trained, these models can be deployed and run locally on a standard desktop or laptop computer.
Running an LLM locally offers several advantages over cloud-based usage:
- Performance: Local interaction eliminates network latency, ensuring instant responses.
- Privacy and Security: Sensitive data stays on the user’s device, preventing unauthorized access.
- Cost: There are no subscription costs to use the LLM. The only cost is the hardware.
- Customization: Users can train the model on their specific data to obtain more relevant results.
- Availability: The LLM remains accessible even offline when there’s no or unstable internet connection.
Thanks to the computing power of modern CPUs and GPUs, even a regular laptop can run highly complex LLMs with hundreds of billions of parameters, allowing the most advanced conversational artificial intelligence to be carried anywhere.
Hugging Face
Hugging Face is an open-source platform aimed at promoting ethical AI development through community-driven sharing of models, datasets, and tools. Founded in 2016, it boasts over half a million users today.
At the core of Hugging Face lies its hub, hosting thousands of pre-trained AI models ready to be used in various applications. It houses cutting-edge deep learning systems for natural language processing and computer vision, featuring architectures like BERT, Llama, StableDiffusion, and many others.
Many models are stored in the GGUF format, ideal for representing neural networks intended for inference. The GGUF (GPT-Generated Unified Format), introduced as the successor to GGML (GPT-Generated Model Language), was released on August 21, 2023. This format marks a significant advancement in file formats for language models, streamlining the storage and optimized processing of large language models like GPT.
Hugging Face’s open mission truly democratizes access to advanced AI. The LM Studio software seamlessly integrates with this platform, enabling the download and local execution of the best open source generative AI.
LM Studio
LM Studio is a software tool that enables downloading and running the most powerful Large Language Models (LLMs) directly on one’s computer, without the need for an internet connection or access to cloud infrastructure.
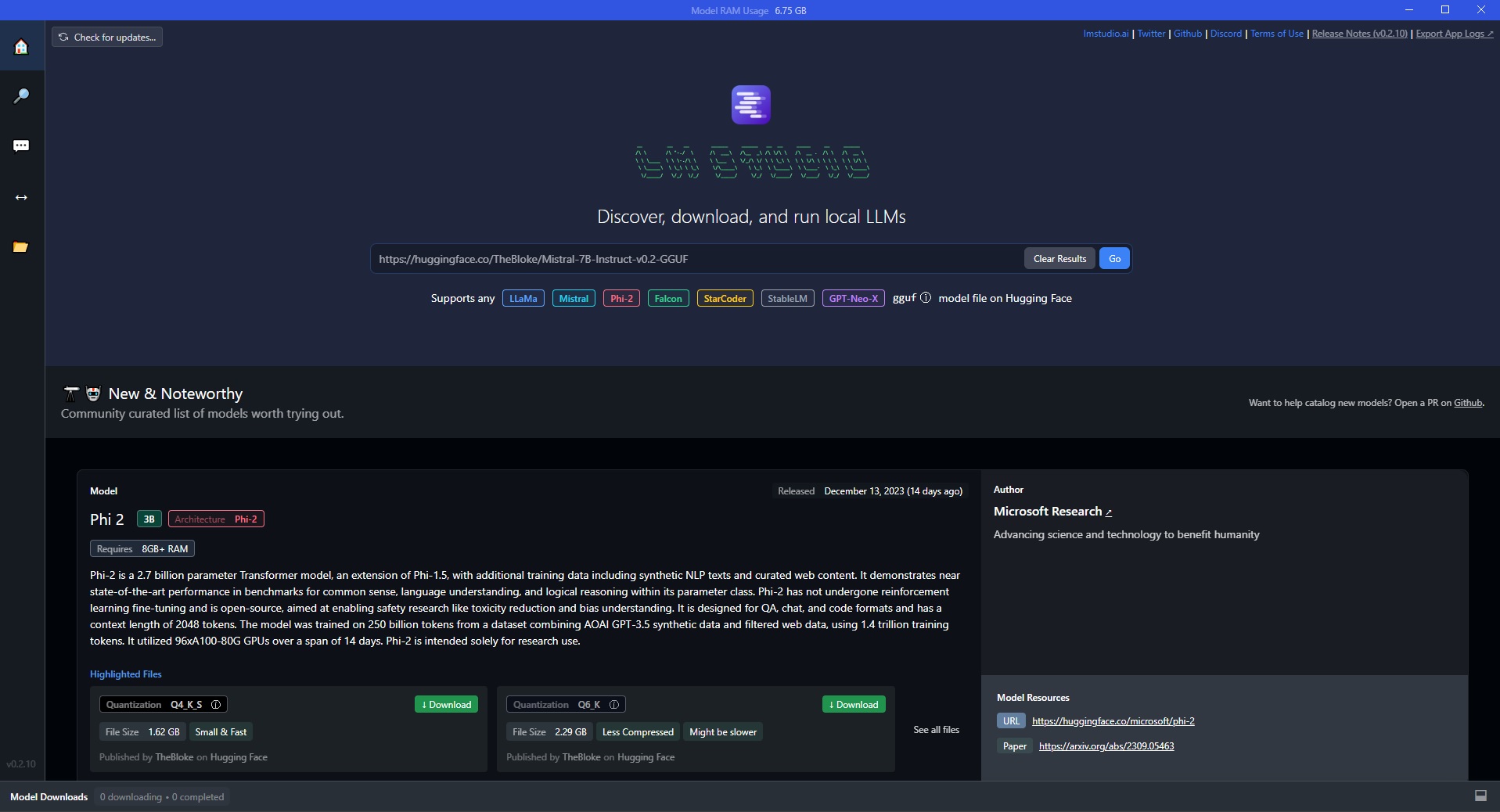
LM Studio provides an intuitive graphical interface to interact with LLMs, ask questions in natural language, and receive detailed responses generated on the fly by the models. The app allows access to the Hugging Face catalog, enabling the download of parameters for top LLMs available, such as LLaMa, Mistral, Phi 2, and many others.
After completing the installation and configuration steps, users can initiate a conversation with the chosen LLM model through LM Studio’s convenient chat interface.
To start a new session, simply click the “AI chat” tab and type the desired message in the text field at the bottom. Upon hitting Enter, the request will be sent to the LLM, which will instantly generate a detailed response.
Users can ask any type of question within the model’s capabilities, such as information requests, contextualization of events, explanations of complex concepts, predictions, practical advice, and much more. The LLM can even generate creative texts like poems, stories, and articles on demand.
A significant advantage of local LLMs is the ability to customize responses further by training the model on proprietary datasets related to one’s business or area of interest, thus obtaining more tailored content to individual needs.
Thanks to its intuitive interface, even less experienced users can benefit from the extraordinary abilities of LLMs to understand and produce human language in a friendly and interactive manner.
Hardware requirements and minimum PC specifications
To make the most of LM Studio’s features and powerful LLM models, a computer with the following minimum specifications is required:
- Dedicated NVIDIA or AMD graphics card with at least 8GB of VRAM
- 16GB of DDR4 or DDR5 RAM
- Processor supporting AVX2 instructions (present in most modern PCs)
Regarding operating systems and software:
- For Windows and Linux, a processor compatible with AVX2 and at least 16GB of RAM is required.
- For macOS, an Apple Silicon M1 chip or later (M2, M3) with macOS 13.6 or newer versions is necessary.
The internal user interface allows interaction with these models in a chat mode, enabling users to ask questions and receive quick and elaborate responses by fully leveraging the power of local hardware, without latency or network issues.
The power of a modern desktop or laptop PC is more than sufficient to run powerful LLMs locally (at least 5-bit quantized versions of about 5/6 GB in size), providing significant benefits in terms of speed, privacy, and customization.
Best GPUs for Local LLMs
When it comes to running Large Language Models (LLMs) locally, the single most important factor to consider is the amount of VRAM (Video Random Access Memory) available on your graphics card. VRAM plays a crucial role in LLM inference, as it determines the size and complexity of the models you can run on your local machine.
For users looking to dive into local LLM inference, here are some GPU options to consider:
Budget-Friendly Option:
NVIDIA RTX 3060 (12 GB VRAM): This graphics card offers a good balance between price and performance. With 12 GB of VRAM, it can handle many quantized LLMs effectively, making it a cost-effective choice for enthusiasts and beginners.
Mid-Range Option:
NVIDIA RTX 4060 Ti (16 GB VRAM): While more expensive than the RTX 3060, this card provides additional VRAM, allowing for larger models or improved performance. However, it may not be as cost-effective as the 3060 for those on a tight budget.
High-Performance Option (on a budget):
Why no AMD cards?
While AMD cards can be viable for inference using ROCm, they may present some compatibility challenges. For users looking to avoid potential issues and ensure smooth operation, NVIDIA cards are generally recommended due to their widespread support and optimization for AI workloads.
By choosing a GPU with ample VRAM, users can unlock the full potential of local LLM inference, enjoying faster processing times and the ability to run more sophisticated models directly on their personal computers.
Advanced Use and Democratization of Artificial Intelligence through Open Source
Local Inference Server
In addition to the conversational chat interface, LM Studio offers developers and advanced users an alternative way to interact with LLM models through its Local Inference Server. This locally initiates an HTTP server that accepts requests and returns responses using an API format compatible with OpenAI.
By invoking the local endpoints with a JSON payload containing the prompt and parameters, the server will forward the input to the chosen LLM and return the generated output. This allows seamless integration of AI capabilities into any customized application designed to work with the OpenAI API, now completely offloaded locally.
The local inference server unlocks advanced natural language generation to enhance next-gen AI assistants, creative tools, and other intelligent applications.
The ability to run powerful language models on local hardware using software like LM Studio, KoboldCpp, Ollama Web UI and SillyTavern, paves the way for exciting use cases that go beyond the traditional chatbot.
LLMs can be integrated into any application requiring conversational AI or text generation components. For instance, virtual assistants for customer service, decision support systems in the medical field and automation of legal and financial workflows through self-generated documentation.
Continual improvements in LLM accessibility due to open-source software and consumer hardware are truly democratizing artificial intelligence. Today, anyone can experience the incredible capabilities of cutting-edge language models simply by using their computer, without relying on third-party cloud servers for data processing.
This grassroots revolution holds promise for a future where AI is accessible to all, not just the realm of governments or mega-corporations, opening new possibilities for startups, indie developers, and enthusiasts.
Read also: How to Prompt LLMs to Generate Content