Cos'è un LLM e a cosa serve
I Large Language Models (LLM) sono modelli di apprendimento automatico addestrati su enormi quantità di dati testuali per comprendere e generare linguaggio naturale. Tra i più noti LLM vi sono ChatGPT, Claude e Gemini. Questi modelli sono in grado di svolgere una varietà di attività come rispondere a domande, riassumere testi, tradurre lingue, analizzare l’intento di ricerca e persino generare nuovi contenuti come articoli, poesie, content marketing e codice informatico.
I LLM vengono tipicamente ospitati su infrastrutture cloud per via delle immense risorse computazionali necessarie durante la fase di addestramento. Tuttavia, una volta addestrati, questi modelli possono essere distribuiti ed eseguiti localmente su un comune PC desktop o portatile.
L’esecuzione in locale di un LLM presenta diversi vantaggi rispetto all’utilizzo basato su cloud:
- Prestazioni: l’interazione locale elimina la latenza di rete, garantendo risposte istantanee.
- Privacy e sicurezza: i dati sensibili non escono dal dispositivo dell’utente, prevenendo accessi non autorizzati.
- Costo: non sono previsti costi di abbonamento per utilizzare l’LLM. L’unico costo è l’hardware.
- Personalizzazione: l’utente può addestrare il modello su propri dati specifici per ottenere risultati più pertinenti.
- Disponibilità: l’LLM rimane accessibile anche offline, quando la connessione Internet è assente o instabile.
Grazie alla potenza di calcolo delle moderne CPU e GPU, anche un comune laptop può eseguire modelli LLM molto complessi con centinaia di miliardi di parametri, permettendo di portare ovunque l’intelligenza artificiale conversazionale più avanzata.
Hugging Face: hub dell'intelligenza artificiale open source
Hugging Face è una piattaforma open source che mira a promuovere lo sviluppo etico dell’IA attraverso la condivisione community-driven di modelli, dataset e strumenti. Fondata nel 2016, conta oggi oltre mezzo milione di utenti.
Cuore pulsante di Hugging Face è il suo hub che ospita migliaia di modelli AI già addestrati, pronti per essere utilizzati in una moltitudine di applicazioni. Vi si trovano i più avanzati sistemi di deep learning per il linguaggio naturale e la computer vision, con architetture quali BERT, Llama, StableDiffusion e molti altri.
Tanti modelli sono memorizzati nel formato GGUF ideale per rappresentare network neurali destinati all’inferenza. Il GGUF (GPT-Generated Unified Format), presentato come successore del GGML (GPT-Generated Model Language), è stato rilasciato il 21 agosto 2023. Questo formato rappresenta un passo avanti significativo nel campo dei formati file per modelli linguistici, facilitando l’archiviazione e l’elaborazione ottimizzate di grandi modelli linguistici come GPT.
La missione open di Hugging Face sta davvero democratizzando l’accesso all’IA avanzata. Il software LM Studio si integra perfettamente con questa piattaforma permettendo di scaricare ed eseguire localmente la migliore IA generativa.
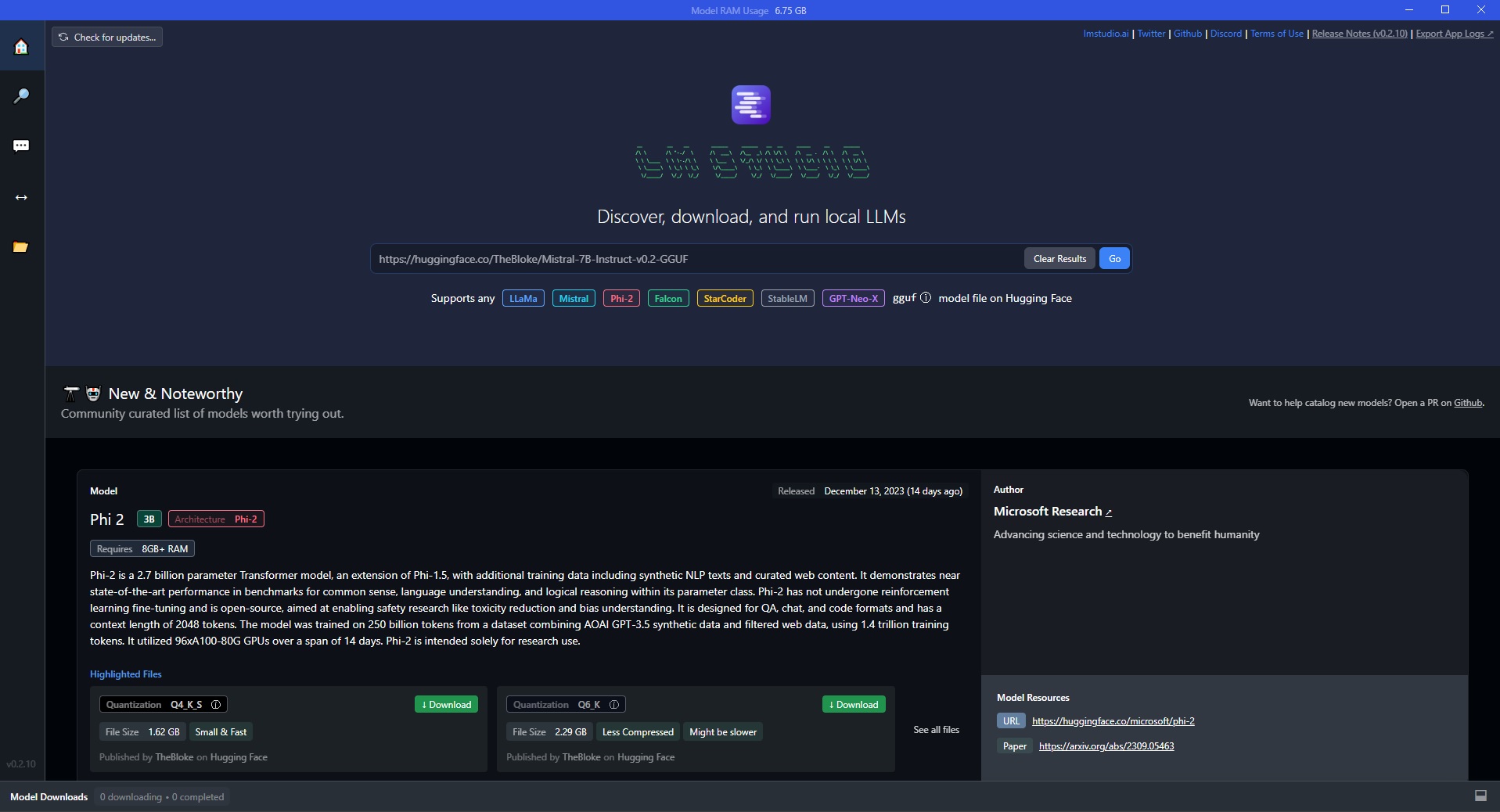
LM Studio
LM Studio è uno strumento software che permette di scaricare ed eseguire i più potenti modelli di linguaggio Large Language Models (LLM) direttamente sul proprio computer, senza necessità di connessione a Internet o accesso a infrastrutture cloud.
LM Studio mette a disposizione un’intuitiva interfaccia grafica per interagire con gli LLM, porre domande in linguaggio naturale e ottenere risposte dettagliate generate al volo dai modelli. L’app consente di accedere al catalogo Hugging Face e scaricare i parametri dei migliori LLM disponibili, come LLaMa, Mistral, Phi 2 e molti altri.
Dopo aver completato i passaggi di installazione e configurazione, è possibile avviare finalmente una conversazione con il modello LLM scelto attraverso la comoda interfaccia chat di LM Studio.
Per iniziare una nuova sessione, è sufficiente cliccare sul pulsante “AI chat” e digitare il messaggio desiderato nel campo di testo in basso. Premendo Invio la richiesta verrà inviata all’LLM che genererà istantaneamente una risposta dettagliata.
È possibile porre qualsiasi tipo di domanda coperta dalle capacità del modello, ad esempio: richieste di informazioni, contestualizzazione di eventi, spiegazioni di concetti complessi, previsioni, consigli pratici e molto altro. L’LLM può anche generare testi creativi come poesie, racconti e articoli su traccia.
Un grande vantaggio degli LLM in locale è la possibilità di personalizzare le risposte addestrando ulteriormente il modello su dataset proprietari legati al proprio business o area di interesse, permettendo così di ottenere contenuti ancor più pertinenti alle necessità individuali.
Grazie all’interfaccia intuitiva, anche gli utenti meno esperti possono trarre beneficio dalle straordinarie capacità degli LLM di comprendere e produrre linguaggio umano in maniera amichevole e interattiva.
Requisiti hardware e specifiche minime del PC
Per sfruttare al meglio le funzionalità di LM Studio e i potenti modelli LLM, è necessario un computer con le seguenti caratteristiche minime:
- Scheda video dedicata NVIDIA o AMD con almeno 8GB di memoria VRAM
- 16GB di RAM DDR4 o DDR5
- Processore che supporti le istruzioni AVX2 (presente nella maggior parte dei PC moderni)
In termini di sistema operativo e software:
- Per Windows e Linux è richiesto un processore compatibile AVX2 e almeno 16GB di RAM
- Per macOS è necessario un chip Apple Silicon M1 o successive (M2, M3) con macOS 13.6 o versioni più recenti
L’interfaccia utente interna permette di interagire con questi modelli in modalità chat, porre domande e ottenere risposte veloci ed elaborate sfruttando appieno la potenza dell’hardware locale, senza latenza o problemi di rete.
La potenza di un moderno PC desktop o laptop è più che sufficiente per eseguire potenti LLM in locale (almeno le versioni quantizzate 5bit di dimensione circa 5/6 GB) con notevoli benefici in termini di velocità, privacy e personalizzazione.
Le migliori schede grafiche per LLM in locale
Quando si tratta di eseguire Modelli Linguistici di Grandi Dimensioni (LLM) localmente, il fattore più importante da considerare è la quantità di VRAM (Video Random Access Memory) disponibile sulla tua scheda grafica.
La VRAM gioca un ruolo cruciale nell’inferenza degli LLM, poiché determina la dimensione e la complessità dei modelli che puoi eseguire sulla tua macchina locale.
Per gli utenti che desiderano immergersi nell’inferenza locale degli LLM, ecco alcune opzioni di GPU da considerare:
Opzione economica:
NVIDIA RTX 3060 (12 GB VRAM): Questa scheda grafica offre un buon equilibrio tra prezzo e prestazioni. Con 12 GB di VRAM, può gestire efficacemente molti LLM quantizzati, rendendola una scelta conveniente per appassionati e principianti.
Opzione di fascia media:
NVIDIA RTX 4060 Ti (16 GB VRAM): Sebbene più costosa della RTX 3060, questa scheda fornisce ulteriore VRAM, consentendo modelli più grandi o prestazioni migliorate. Tuttavia, potrebbe non essere così conveniente come la 3060 per chi ha un budget limitato.
Opzione ad alte prestazioni (on a budget):
NVIDIA RTX 3090 (24 GB GDDR6X): Per gli utenti che cercano più potenza e capacità di VRAM, una RTX 3090 usata può essere un’eccellente scelta. I suoi 24 GB di VRAM GDDR6X consentono di eseguire modelli più grandi e complessi con facilità. Questa opzione è ideale per chi richiede prestazioni massime e non è disposto a spendere il doppio per una RTX 4090.
Perché nessuna scheda AMD?
Sebbene le schede AMD possano essere valide per l’inferenza utilizzando ROCm, potrebbero presentare alcune sfide di compatibilità.
Per gli utenti che desiderano evitare potenziali problemi e garantire un funzionamento fluido, le schede NVIDIA sono generalmente raccomandate grazie al loro ampio supporto e all’ottimizzazione per i carichi di lavoro AI.
Scegliendo una GPU con ampia VRAM, gli utenti possono sbloccare il pieno potenziale dell’inferenza locale degli LLM, godendo di tempi di elaborazione più rapidi e della capacità di eseguire modelli più sofisticati direttamente sui loro computer personali.
Utilizzi avanzati e la democratizzazione dell'intelligenza artificiale con l'open source
Local Inference Server
Oltre all’interfaccia chat conversazionale, LM Studio offre agli sviluppatori e utenti avanzati un modo alternativo di interagire con i modelli LLM attraverso il suo Local Inference Server. Questo avvia a livello locale un server HTTP che accetta richieste e restituisce risposte utilizzando un formato API compatibile con OpenAI.
Richiamando gli endpoint locali con un payload JSON contenente il prompt e i parametri, il server inoltrerà l’input al LLM scelto e restituirà l’output generato. Ciò consente di integrare in modo trasparente le capacità AI in qualsiasi applicazione personalizzata progettata per funzionare con l’API di OpenAI, ora completamente offloadata in locale.
Il local inference server sblocca la generazione avanzata in linguaggio naturale per potenziare assistenti AI next-gen, tool creativi e altre applicazioni intelligenti.
L’abilità di eseguire potenti modelli di linguaggio su hardware locale grazie a software come LM Studio, KoboldCpp, Ollama Web UI, SillyTavern, apre la strada a entusiasmanti casi d’uso che vanno ben oltre la classica chatbot.
Gli LLM possono essere integrati in qualsiasi applicazione che richieda una componente di intelligenza artificiale conversazionale o generazione di testi. Per esempio, assistenti virtuali per il customer service, sistemi di supporto alle decisioni in ambito medico, automazione di workflow legali e finanziari tramite documentazione autogenerata.
I continui miglioramenti nell’accessibilità degli LLM grazie al software open source e all’hardware da consumo stanno davvero democratizzando l’intelligenza artificiale. Oggi chiunque può sperimentare le incredibili capacità di modelli linguistici d’avanguardia semplicemente utilizzando il proprio computer, senza delegare i dati a server cloud di terze parti.
Questa rivoluzione “dal basso” fa ben sperare per un futuro in cui l’IA sia alla portata di tutti e non solo appannaggio di governi o megacorporation, aprendo nuove possibilità per startup, developer indie e appassionati.
Leggi anche: Prompt efficaci per generare contenuti con i LLM