Perché Python per la SEO
L’ottimizzazione per i motori di ricerca è un campo dinamico in cui rimanere competitivi è fondamentale. Negli ultimi anni, un potente alleato è emerso per i professionisti SEO: Python. Questo versatile linguaggio di programmazione sta rapidamente diventando uno strumento imprescindibile nel kit di strumenti SEO. Ma perché Python sta guadagnando così tanta trazione nella comunità SEO?
La rilevanza di Python nella SEO deriva dalla sua capacità di automatizzare e scalare varie attività SEO. Dall’analisi dei dati al web scraping, Python consente agli esperti SEO di gestire grandi quantità di dati, eseguire calcoli complessi e semplificare attività ripetitive.
È come avere un coltellino svizzero per il marketing digitale: adattabile, affidabile e incredibilmente utile per una vasta gamma di sfide SEO. Dall’analisi delle prestazioni del sito web all’automazione delle attività noiose, Python sta aiutando i professionisti SEO a lavorare in modo più intelligente, non più duro.
- Automazione delle attività ripetitive: Gli script Python possono automatizzare attività che richiedono tempo come la ricerca di parole chiave, l’analisi dei contenuti e gli audit dei backlink, liberando tempo prezioso per la strategia e il pensiero creativo.
- Analisi dei dati su larga scala: Con librerie come pandas, i professionisti SEO possono analizzare enormi quantità di dati rapidamente, scoprendo intuizioni che sarebbe impraticabile trovare manualmente.
- Capacità di web scraping: Le librerie di Python come BeautifulSoup e Scrapy rendono facile estrarre dati dai siti web, cruciale per l’analisi dei concorrenti e la ricerca dei contenuti.
- Integrazione API: Molti strumenti e piattaforme SEO offrono API che possono essere facilmente accessibili utilizzando Python, consentendo report personalizzati e integrazione dei dati.
- Soluzioni personalizzabili: La flessibilità di Python permette ai professionisti SEO di creare soluzioni su misura per problemi unici, andando oltre i limiti degli strumenti SEO commerciali.
Sfruttando Python, i professionisti SEO possono non solo migliorare la loro efficienza ma anche ottenere intuizioni più profonde sui loro dati, portando a strategie più informate e migliori risultati.
Iniziare con Python per la SEO
Introduzione a Jupyter Notebooks
Uno dei modi migliori per iniziare a usare Python per la SEO è attraverso i Jupyter Notebooks. I Jupyter Notebooks forniscono un ambiente interattivo in cui è possibile scrivere ed eseguire codice Python, visualizzare i dati e documentare il processo tutto in un unico posto.
Caratteristiche principali dei Jupyter Notebooks per il lavoro SEO:
- Coding Interattivo: Esegui singole celle di codice, consentendo un’analisi passo-passo e un debug facile. (questo è molto importante per un principiante in quanto aiuta a comprendere la logica passo dopo passo)
- Output multimediale ricco: Visualizza grafici, tabelle e altro direttamente nel notebook, rendendo la visualizzazione dei dati senza soluzione di continuità.
- Supporto Markdown: Aggiungi spiegazioni e note utilizzando Markdown, creando analisi SEO auto-documentanti.
- Formato condivisibile: Condividi facilmente il tuo lavoro con i membri del team o i clienti in un formato che combina codice, output e spiegazioni.
Configurazione dell'ambiente
Anaconda
Iniziare con Python per la SEO è più facile di quanto si possa pensare, grazie a Anaconda. Anaconda è una distribuzione gratuita e open-source di Python che viene pre-caricata con molte delle librerie necessarie per il lavoro SEO, incluso Jupyter Notebook. Ecco come configurarlo:
- Scarica Anaconda: Visita il sito ufficiale di Anaconda e scarica la versione appropriata per il tuo sistema operativo (Windows, macOS o Linux).
- Installa Anaconda: Esegui il programma di installazione e segui le istruzioni. Le impostazioni predefinite sono generalmente adatte alla maggior parte degli utenti.
- Avvia Jupyter Notebook: Dopo l’installazione, puoi avviare Jupyter Notebook da Anaconda Navigator o digitando
jupyter notebooknel prompt dei comandi o nel terminale.
Ecco fatto! Con Anaconda, ora hai Python, Jupyter Notebook e molte librerie essenziali (come pandas e matplotlib) pronti per l’uso. Questa soluzione all-in-one ti risparmia la seccatura di installare Python e i singoli pacchetti separatamente.
Per le librerie specifiche per la SEO che potrebbero non essere incluse nella distribuzione predefinita di Anaconda (come requests o beautifulsoup4), puoi installarle facilmente utilizzando il gestore dei pacchetti di Anaconda. Basta aprire il prompt di Anaconda e digitare:
conda install requests beautifulsoup4
Oppure, se preferisci usare pip:
pip install requests beautifulsoup4
Con questa configurazione, sei pronto per iniziare il tuo viaggio SEO con Python senza il mal di testa di installazioni complesse o problemi di compatibilità. Nella sezione successiva, esploreremo alcune delle principali librerie Python che superchargeranno i tuoi flussi di lavoro SEO.
Librerie Python Utili per la SEO
La potenza di Python per la SEO risiede non solo nel linguaggio stesso, ma nel suo ricco ecosistema di librerie. Ecco alcune delle librerie più utili per i professionisti SEO:
Pandas
Pandas è il coltellino svizzero della manipolazione dei dati in Python. Fornisce strutture dati per memorizzare in modo efficiente grandi dataset e strumenti per lavorare con dati strutturati. Per la SEO, Pandas è inestimabile per compiti come analizzare grandi elenchi di parole chiave, elaborare esportazioni CSV da vari strumenti SEO o manipolare dati da Google Analytics. Con Pandas, puoi facilmente unire dataset, filtrare dati, eseguire calcoli tra colonne e creare tabelle pivot. La sua capacità di gestire grandi dataset lo rende perfetto per lavorare con il volume di dati spesso incontrato nelle attività SEO.
Requests
La libreria Requests è la tua porta d’accesso per interagire con servizi web e API. Semplifica il processo di invio di richieste HTTP/1.1, essenziale per compiti come il recupero di pagine web per l’analisi o l’interazione con le API degli strumenti SEO. Con Requests, puoi facilmente recuperare l’HTML di una pagina web, controllare i codici di stato o inviare dati alle API. Questa libreria è spesso il punto di partenza per le attività di web scraping ed è cruciale per automatizzare le interazioni con vari servizi web utilizzati nella SEO.
BeautifulSoup
BeautifulSoup è una libreria per estrarre dati da file HTML e XML. Funziona con il tuo parser preferito per fornire modi idiomatici di navigare, cercare e modificare l’albero di parsing. Per la SEO, BeautifulSoup è incredibilmente utile per compiti come l’estrazione di elementi specifici dalle pagine web (ad esempio, tag title, meta descrizioni, intestazioni), l’analisi dei fattori SEO on-page o il scraping dei siti web dei concorrenti. Quando combinato con Requests, BeautifulSoup diventa uno strumento potente per automatizzare la raccolta di dati web rilevanti per l’analisi SEO.
Advertools
Advertools è una libreria specificamente progettata per i marketer digitali e i professionisti SEO. Fornisce una vasta gamma di funzioni per varie attività SEO, tra cui la generazione di parole chiave, l’analisi dei testi e il crawling dei siti web. Con Advertools, puoi facilmente generare combinazioni di parole chiave, analizzare le pagine dei risultati dei motori di ricerca (SERP), estrarre dati strutturati dalle pagine web e persino creare report SEO. Le sue funzioni incentrate sulla SEO lo rendono un’aggiunta preziosa al toolkit di qualsiasi professionista SEO esperto in Python.
Plotly
La visualizzazione dei dati è cruciale nella SEO per comprendere le tendenze e comunicare intuizioni. Plotly è una libreria che crea visualizzazioni belle e interattive. Con Plotly, puoi creare una vasta gamma di grafici e tabelle, dai semplici grafici a linee ai complessi heatmap. Per la SEO, questo è particolarmente utile per visualizzare le tendenze delle parole chiave, i profili dei backlink o i modelli di traffico del sito web. La natura interattiva delle visualizzazioni di Plotly le rende eccellenti per presentazioni ai clienti o dashboard del team.
NLTK (Natural Language Toolkit)
Il Natural Language Toolkit (NLTK) è una piattaforma leader per costruire programmi Python per lavorare con i dati del linguaggio umano. Nella SEO, NLTK può essere utilizzato per attività avanzate di analisi dei contenuti. Fornisce strumenti per la tokenizzazione, lo stemming, il tagging, il parsing e il ragionamento semantico. Questo lo rende prezioso per compiti come l’analisi della leggibilità dei contenuti, l’estrazione di frasi chiave da grandi quantità di testo o persino lo sviluppo di strumenti di ottimizzazione dei contenuti più sofisticati. Sebbene abbia una curva di apprendimento più ripida rispetto ad altre librerie, NLTK apre possibilità per l’elaborazione avanzata del linguaggio naturale nella SEO.
Streamlit
Sebbene non sia strettamente uno strumento SEO, Streamlit è incredibilmente utile per creare rapidamente app web per progetti di data science e machine learning. Per i professionisti SEO che utilizzano Python, Streamlit fornisce un modo semplice per trasformare gli script di dati in app web condivisibili. Questo può essere particolarmente utile per creare dashboard interattivi per i dati SEO, costruire strumenti per i membri del team che potrebbero non essere a proprio agio con Python o presentare report interattivi ai clienti. Con Streamlit, puoi trasformare i tuoi script SEO in applicazioni user-friendly con un minimo di codice aggiuntivo.
Ognuna di queste librerie porta capacità uniche al tuo toolkit SEO in Python. Combinandole, puoi creare soluzioni potenti e personalizzate per una vasta gamma di attività SEO, dalla raccolta e analisi dei dati alla visualizzazione e reportistica. Nella prossima sezione, metteremo in pratica alcune di queste librerie in un esempio pratico, dimostrando come Python può risolvere sfide SEO del mondo reale.
Strumento di Analisi dei Contenuti Web
Immergiamoci in un esempio pratico in Jupyter Notebook che dimostra come possiamo utilizzare le librerie Python per creare uno strumento di analisi dei contenuti web. Questo strumento può essere utile per analizzare il contenuto delle pagine web, identificare le parole chiave e le frasi più frequentemente utilizzate e visualizzare i risultati.
Questo strumento:
- Effettua lo scraping del contenuto di una determinata pagina web
- Elabora il testo per rimuovere le parole comuni (stop words)
- Analizza la frequenza delle singole parole, delle frasi di due parole (bigrammi) e delle frasi di tre parole (trigrammi)
- Visualizza i risultati in tabelle facili da leggere
- Visualizza i dati con una word cloud e treemap interattivi
Questo script dimostrerà tecniche di base di web scraping, elaborazione del testo, analisi dei dati e visualizzazione utilizzando librerie Python popolari come requests, BeautifulSoup, NLTK, pandas e Plotly.
Configurazione dell'ambiente
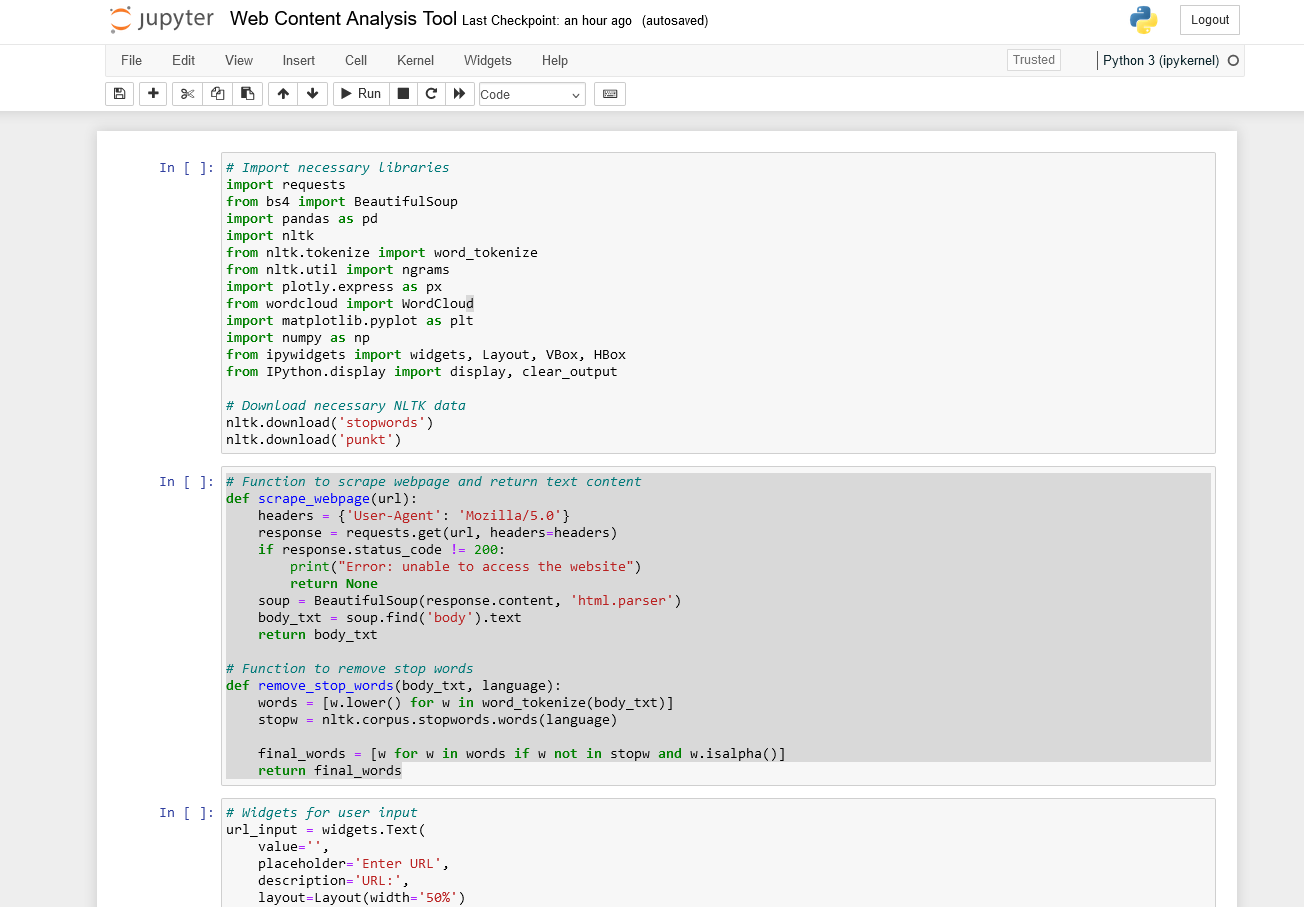
Per prima cosa, importiamo le librerie necessarie: (copia e incolla ciascuna di queste sezioni in diverse celle del Notebook)
import requests
from bs4 import BeautifulSoup
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
from nltk.util import ngrams
import plotly.express as px
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from ipywidgets import widgets, Layout, VBox, HBox
from IPython.display import display, clear_output
nltk.download('stopwords')
nltk.download('punkt')
Ecco cosa fa ciascuna libreria:
- requests: Per effettuare richieste HTTP alle pagine web
- BeautifulSoup: Per analizzare il contenuto HTML
- pandas: Per la manipolazione e l’analisi dei dati
- nltk: Per i compiti di elaborazione del linguaggio naturale
- plotly.express: Per creare visualizzazioni interattive
- WordCloud: Per generare word cloud
- matplotlib: Per creare visualizzazioni statiche
- ipywidgets: Per creare elementi UI interattivi nei notebook Jupyter
Scarichiamo anche i dati necessari per NLTK.
Core Functions
# Funzione per fare lo scraping della pagina web e restituire il contenuto del testo
def scrape_webpage(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Error: unable to access the website")
return None
soup = BeautifulSoup(response.content, 'html.parser')
body_txt = soup.find('body').text
return body_txt
# Funzione per rimuovere le stop words
def remove_stop_words(body_txt, language):
words = [w.lower() for w in word_tokenize(body_txt)]
stopw = nltk.corpus.stopwords.words(language)
final_words = [w for w in words if w not in stopw and w.isalpha()]
return final_words
Lo script definisce due funzioni principali:
- scrape_webpage(url): Questa funzione prende un URL come input, invia una richiesta alla pagina web e restituisce il contenuto testuale del corpo. Utilizza un User-Agent personalizzato per imitare una richiesta del browser.
- remove_stop_words(body_txt, language): Questa funzione tokenizza il testo, rimuove le stop words (parole comuni come “il”, “è”, ecc.) e restituisce un elenco di parole significative. Supporta più lingue.
Interfaccia Utente
# Widgets per l'input dell'utente
url_input = widgets.Text(
value='',
placeholder='Enter URL',
description='URL:',
layout=Layout(width='50%')
)
language_input = widgets.Dropdown(
options=['english', 'italian'],
value='english',
description='Language:',
layout=Layout(width='50%')
)
num_results_input = widgets.IntSlider(
value=50,
min=10,
max=150,
step=10,
description='Results:',
layout=Layout(width='50%')
)
analyze_button = widgets.Button(
description='Analyze',
button_style='primary',
layout=Layout(width='30%')
)
output_area = widgets.Output()
# Function to handle button click
def on_analyze_button_clicked(b):
with output_area:
clear_output()
url = url_input.value
language = language_input.value
n = num_results_input.value
if not url:
print("Insert a URL")
return
body_txt = scrape_webpage(url)
if not body_txt:
return
final_words = remove_stop_words(body_txt, language)
# Store results in global variables
global df1, df2, df3, all_final_words, all_body_txt
all_final_words = final_words
all_body_txt = body_txt
# Bigrams
bigrams = ngrams(final_words, 2)
freq_bigrams = nltk.FreqDist(bigrams)
bigrams_freq = freq_bigrams.most_common(n)
# Keyword frequency
freq = nltk.FreqDist(final_words)
keywords = freq.most_common(n)
# ngrams = 3
ngrams3 = ngrams(final_words, 3)
freq_ngrams3 = nltk.FreqDist(ngrams3)
ngrams3_freq = freq_ngrams3.most_common(n)
# Creating pandas dataframes
df1 = pd.DataFrame(keywords, columns=("Keyword", "Frequency"))
df2 = pd.DataFrame(bigrams_freq, columns=("Bigram", "Frequency"))
df3 = pd.DataFrame(ngrams3_freq, columns=("Ngrams3", "Frequency"))
print("Data scraped and processed. You can now execute the subsequent cells to see the results.")
# Collega l'event handler al pulsante
analyze_button.on_click(on_analyze_button_clicked)
# Mostra l'interfaccia utente
ui = VBox([HBox([url_input, language_input]), num_results_input, HBox([analyze_button]), output_area])
display(ui)
Lo script crea un’interfaccia utente interattiva utilizzando ipywidgets. Gli utenti possono inserire:
- URL della pagina web da analizzare
- Lingua del contenuto
- Numero di risultati da visualizzare
Un pulsante “Analyze” avvia il processo di analisi.
Processo di Analisi
Quando l’utente clicca su “Analyze”, lo script:
Effettua lo scraping della pagina web
Rimuove le stop words
Genera distribuzioni di frequenza per: singole parole chiave, Bigrammi (frasi di due parole), Trigrammi (frasi di tre parole)
Crea DataFrame pandas con i risultati
Visualizzazioni
# Visualizza la frequenza delle parole chiave
display(df1)
# Grafico Treemap per le Parole Chiave
fig = px.treemap(df1[:30], path=[px.Constant("Key Frequency"), "Keyword"],
values='Frequency', color='Frequency',
color_continuous_scale='viridis',
color_continuous_midpoint=np.average(df1['Frequency']))
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show()
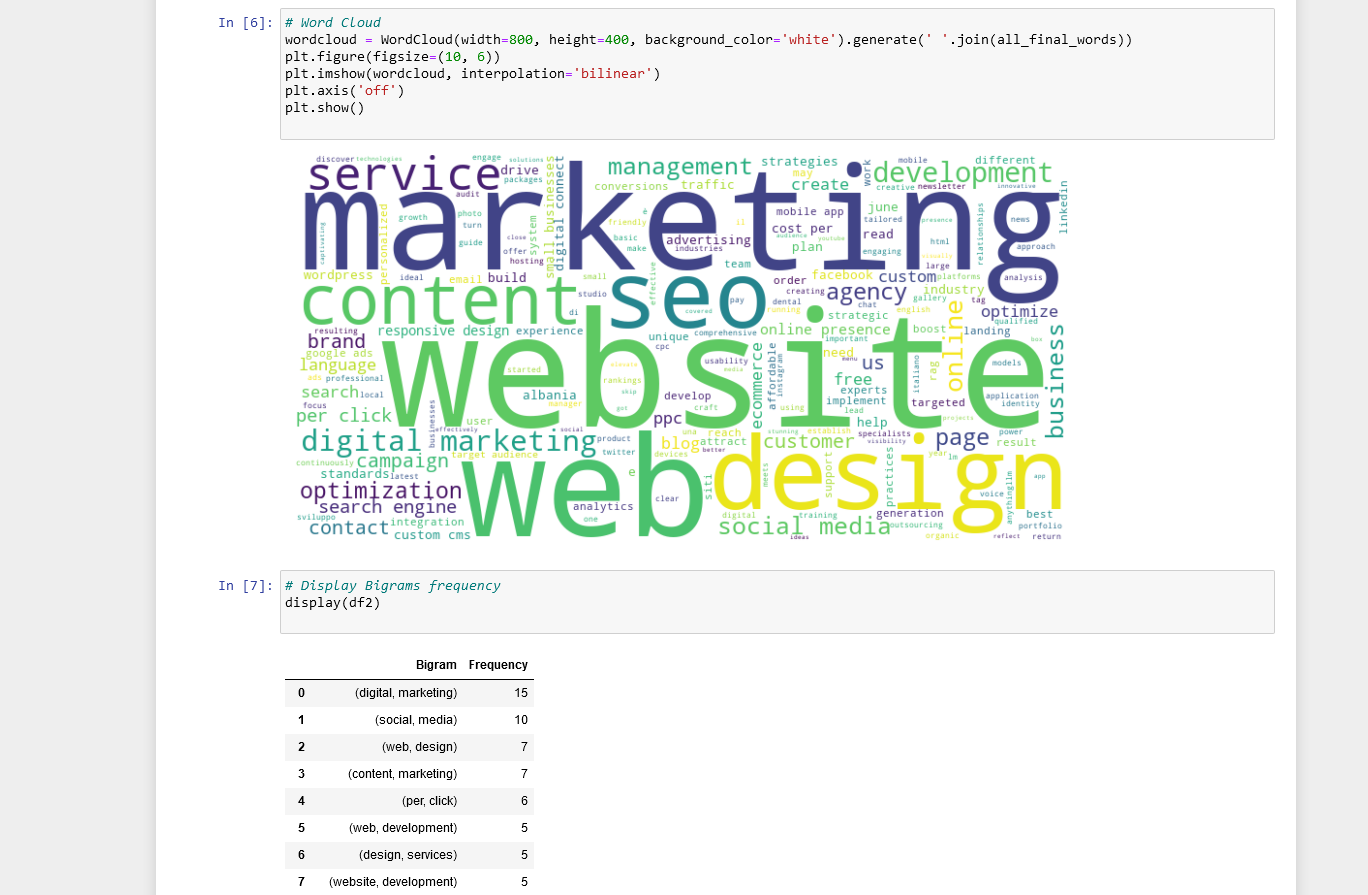
# Word Cloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(' '.join(all_final_words))
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# Visualizza la frequenza dei Bigrammi
display(df2)
# Grafico Treemap per i Bigrammi
fig = px.treemap(df2[:30], path=[px.Constant("Bigram Frequency"), "Bigram"],
values='Frequency', color='Frequency',
color_continuous_scale='viridis',
color_continuous_midpoint=np.average(df2['Frequency']))
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show()
# Visualizza la frequenza dei Trigrammi
display(df3)
Il notebook fornisce diverse visualizzazioni dei dati analizzati:
- Tabella della Frequenza delle Parole Chiave: Mostra le parole singole più comuni e le loro frequenze.
- Treemap per le Parole Chiave: Una visualizzazione interattiva delle prime 30 parole chiave, dove la dimensione e il colore di ogni riquadro rappresentano la frequenza della parola chiave.
- Word Cloud: Una rappresentazione visiva in cui la dimensione di ciascuna parola indica la sua frequenza nel testo.
- Tabella della Frequenza dei Bigrammi: Mostra le frasi di due parole più comuni.
- Treemap per i Bigrammi: Simile al treemap delle parole chiave, ma per le frasi di due parole.
- Tabella della Frequenza dei Trigrammi: Mostra le frasi di tre parole più comuni.
Apprendimento dei Concetti SEO attraverso Python
Questo script serve come punto di partenza per chi vuole imparare Python per la SEO. Sebbene non sia uno strumento professionale, dimostra diversi concetti che sono preziosi nel lavoro SEO:
- Analisi dei Contenuti di Base: Vedi come puoi estrarre e analizzare i principali argomenti di una pagina web.
- Introduzione all’Analisi delle Parole Chiave: Impara come identificare le parole e le frasi comunemente utilizzate su una pagina web.
- Pratica di Visualizzazione dei Dati: Sperimenta con la creazione di semplici visualizzazioni delle frequenze delle parole.
- Nozioni di Base sul Web Scraping: Comprendi i fondamenti di come recuperare e analizzare i contenuti web.
- Elaborazione del Testo: Ottieni esperienza pratica con le tecniche di base di elaborazione del linguaggio naturale.
- Manipolazione dei Dati: Pratica a lavorare con i dati utilizzando DataFrame pandas.
Sperimentando con questo script, puoi iniziare a comprendere come Python può essere applicato alle attività SEO. È un ottimo modo per familiarizzare con le librerie e i concetti chiave prima di passare ad applicazioni più complesse.
Ricorda, questo è uno strumento di apprendimento, non un sostituto per l’analisi SEO professionale. Man mano che diventi più a tuo agio con Python, puoi ampliare questi concetti per creare strumenti più sofisticati e su misura per le tue esigenze SEO.
Leggi anche: Come scrivere prompt efficaci per i LLM
Parliamone
Se stai cercando di sviluppare uno strumento Python personalizzato su misura per le tue specifiche sfide SEO, siamo qui per aiutarti.