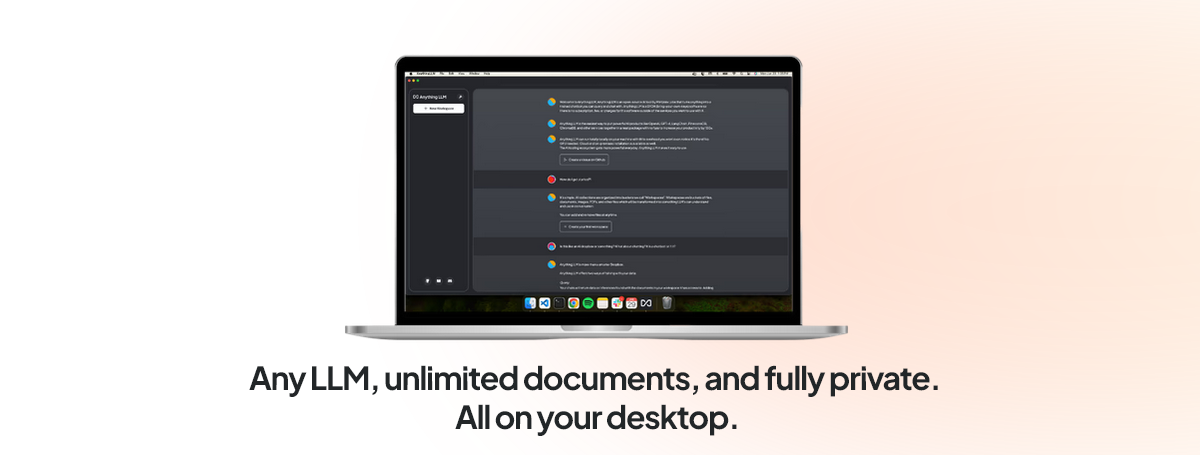
In questo tutorial, ti guideremo attraverso il processo di configurazione di un sistema di Retrieval-Augmented Generation (RAG) utilizzando LM Studio e Anything LLM.
Implementare un RAG di base con AnythingLLM è un processo semplice che non richiede competenze di programmazione o conoscenze esperte di machine learning. AnythingLLM fornisce un’interfaccia user-friendly e un flusso di lavoro semplificato, permettendoti di sfruttare la potenza della Generazione Potenziata dal Recupero (RAG) nel tuo ambiente locale con uno sforzo minimo.
COS'È LA RAG?
La Retrieval-Augmented Generation (RAG) è una tecnica che migliora le capacità dei grandi modelli di linguaggio (LLM) permettendo loro di recuperare e incorporare informazioni rilevanti da fonti esterne durante il processo di generazione.
I tradizionali LLM, sebbene impressionanti nelle loro abilità di comprensione e generazione del linguaggio, sono limitati dalle conoscenze contenute nei loro dati di addestramento. RAG affronta questa limitazione fornendo un meccanismo per i LLM di recuperare dinamicamente e integrare informazioni rilevanti da fonti esterne, come documenti (pdf, doc), siti web o database.
L’importanza di RAG per i LLM non può essere sottovalutata. Sfruttando fonti di conoscenza esterne, RAG consente ai LLM di produrre risposte più accurate, informative e aggiornate. Questo è particolarmente cruciale in ambiti in cui le informazioni fattuali sono essenziali, come i sistemi di risposta alle domande, il recupero delle informazioni e le applicazioni knowledge-intensive.
Senza RAG, i LLM potrebbero generare risposte basate esclusivamente sui loro dati di addestramento, che possono rapidamente diventare obsoleti o mancare di dettagli specifici. RAG mitiga questo problema permettendo ai LLM di accedere e incorporare le informazioni più recenti da fonti esterne, garantendo che le loro risposte siano più accurate e rilevanti.
AnythingLLM
AnythingLLM è un’applicazione full-stack che ti permette di eseguire localmente grandi modelli di linguaggio (LLM) e migliorarne le capacità con varie funzionalità, incluse la RAG e le funzionalità di agente. Funge da ponte tra il tuo LLM e le risorse esterne, abilitando un’integrazione e un potenziamento senza soluzione di continuità delle risposte del modello.
Funzionalità chiave di AnythingLLM:
- Generazione Potenziata dal Recupero (RAG): AnythingLLM abilita le capacità RAG per i tuoi LLM ospitati localmente, permettendo loro di recuperare e incorporare informazioni rilevanti da documenti o fonti esterne durante il processo di generazione.
- Funzionalità di Agente: AnythingLLM introduce funzionalità di agente per i tuoi LLM, dando loro il potere di eseguire vari compiti oltre la semplice generazione di testo, come web scraping, riepilogo, generazione di grafici e manipolazione di file.
- Distribuzione Locale: AnythingLLM funziona interamente sulla tua macchina locale o rete, garantendo privacy e sicurezza dei dati.
- Supporto Multi-Piattaforma: Supporta più sistemi operativi, inclusi Windows, macOS e Linux.
- Open Source: AnythingLLM è un progetto open-source, permettendoti di personalizzare ed estendere le sue funzionalità secondo necessità.
Nella prossima sezione, ti guideremo attraverso il processo di configurazione dell’ambiente necessario, inclusa l’installazione di LM Studio (o Ollama), il download e la configurazione dei modelli LLM, e l’installazione di AnythingLLM.
REQUISITI HARDWARE
Prima di iniziare, assicurati di avere i seguenti requisiti:
Hardware:
- CPU: Un processore moderno multi-core
- RAM: Almeno 16GB (consigliati 32GB o più)
- Scheda Grafica: Preferibilmente una GPU NVIDIA con almeno 8GB di VRAM per prestazioni migliori. Tuttavia, sono supportate anche configurazioni solo CPU con modelli quantizzati.
CONFIGURAZIONE DELL'AMBIENTE
In precedenza abbiamo trattato il processo di installazione di LM Studio in un articolo separato. Se non hai ancora configurato LM Studio, consulta quell’articolo per istruzioni dettagliate. LM Studio ti permette di ospitare e servire modelli LLM localmente sui tuoi dispositivi personali, garantendo privacy e controllo dei dati.
Scaricamento e Configurazione dei Modelli LLM
Una volta installato LM Studio, il passo successivo è scaricare e configurare il/i modello/i LLM che vuoi utilizzare. LM Studio supporta vari modelli, inclusi LLaMa 3 e altri.
- Apri l’applicazione LM Studio e vai alla sezione “Modelli”.
- Sfoglia i modelli disponibili e seleziona quello che vuoi scaricare. (ti consigliamo l’ultimo Llama-3-8B-Instruct-GGUF come buon punto di partenza e abbiamo anche ottenuto buoni risultati con Hermes-2-Pro-Mistral-7B-GGUF)
- Scegli il livello di quantizzazione appropriato per il tuo modello. La quantizzazione è il processo di compressione delle dimensioni del modello per renderlo più efficiente per la distribuzione locale. Livelli di quantizzazione più alti (ad es. Q8) forniscono prestazioni migliori ma richiedono più VRAM + RAM di sistema, mentre livelli più bassi (ad es. Q4 o Q5) hanno dimensioni dei file più piccole ma potrebbero compromettere la qualità.
- Vai alla scheda Server Locale (sulla sinistra), carica qualsiasi LLM che hai scaricato scegliendo dal menu a tendina e avvia il server cliccando sul pulsante verde Avvia Server.
INSTALLAZIONE DI ANYTHINGLLM
Segui questi passaggi per installare AnythingLLM. Una volta installato AnythingLLM, dovrai configurarlo per connetterlo alla tua istanza di LM Studio e al modello LLM che hai scaricato in precedenza. Il processo di configurazione iniziale ti guiderà attraverso questi passaggi.
- Visita il sito web di AnythingLLM e vai alla sezione “Download“.
- Seleziona la versione appropriata per il tuo sistema operativo (Windows, macOS o Linux) e scarica il programma di installazione.
- Esegui il programma di installazione e segui le istruzioni a schermo per completare il processo di installazione.
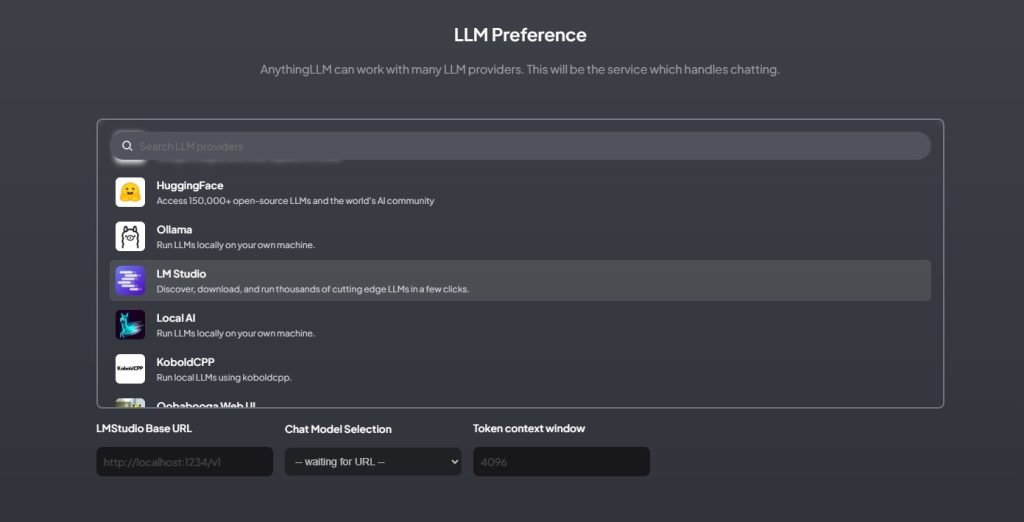
- Quando ti verrà chiesto di scegliere il servizio che gestisce la chat, scegli LM Studio (screenshot sotto) e poi fornisci l’URL Base di LMStudio (che dovrebbe essere il server locale che abbiamo già avviato: http://localhost:1234/v1)
Con l’ambiente configurato, sei ora pronto a implementare RAG utilizzando AnythingLLM e sfruttare la potenza dei LLM ospitati localmente potenziati con funzionalità di recupero di conoscenze esterne. Nella prossima sezione, ci immergeremo nel processo di implementazione di RAG con AnythingLLM, coprendo il caricamento dei documenti, la creazione dell’area di lavoro e l’invio di query con RAG.
IMPLEMENTAZIONE DI RAG CON ANYTHINGLLM
Caricamento dei documenti
Il primo passo per implementare RAG con AnythingLLM è caricare i documenti o le fonti da cui vuoi che il tuo LLM recuperi informazioni. AnythingLLM supporta vari formati di file, inclusi PDF, TXT e altro.
- Avvia l’applicazione AnythingLLM e vai alla sezione “Documenti”.
- Clicca sul pulsante “Carica” e seleziona i file che vuoi aggiungere.
- Una volta caricati i file, selezionali e clicca su “Sposta nell’area di lavoro” e infine “Salva e incorpora“. AnythingLLM li elaborerà e creerà embedding, che sono rappresentazioni vettoriali del contenuto testuale. Questi embedding vengono utilizzati per un recupero efficiente durante il processo RAG.
Creazione di un’area di lavoro
In AnythingLLM, le aree di lavoro fungono da contenitori per i tuoi documenti e conversazioni con il LLM. Per creare una nuova area di lavoro:
- Clicca sulla scheda “Aree di lavoro”.
- Clicca sul pulsante “Crea area di lavoro”.
- Fornisci un nome per la tua nuova area di lavoro.
- Seleziona i documenti che vuoi includere in questa area di lavoro dall’elenco dei documenti caricati.
Con l’implementazione RAG di AnythingLLM, puoi sfruttare le capacità di comprensione e generazione del linguaggio del tuo LLM ospitato localmente migliorando al contempo le sue risposte con informazioni rilevanti da fonti esterne, ottenendo output più accurati, informativi e aggiornati.
Astraendo le complessità, AnythingLLM abilita gli utenti senza competenze di codifica o machine learning a sfruttare la potenza di RAG nel loro ambiente locale. Questo non solo migliora le capacità dei loro LLM ospitati localmente, ma garantisce anche la privacy e il controllo dei dati, poiché l’intero processo viene eseguito sui loro dispositivi o reti personali.